Discrete GCBF proximal policy optimization for multi-agent safe optimal control
REALM researchers present an algorithm for learning distributed, intelligent, and safe policies for multi-agent systems. The work combines control barrier functions with modern multi-agent reinforcement learning techniques to ensure that agents learn to finish a task safely when given a cost function describing a collaborative task.
Authors: Songyuan Zhang, Oswin So, Mitchell Black, and Chuchu Fan
Citation: International Conference on Learning Representations (ICLR) 2025
Abstract:
Control policies that can achieve high task performance and satisfy safety contraints are desirable for any system, including multi-agent systems (MAS). One promising technique for ensuring the safety of MAS is distributed control barrier functions (CBF). However, it is difficult to design distributed CBF-based policies for MAS that can tackle unknown discrete-time dynamics, partial observability, changing neighborhoods, and input constraints, especially when a distributed high-performance nominal policy that can achieve the task is unavailable.
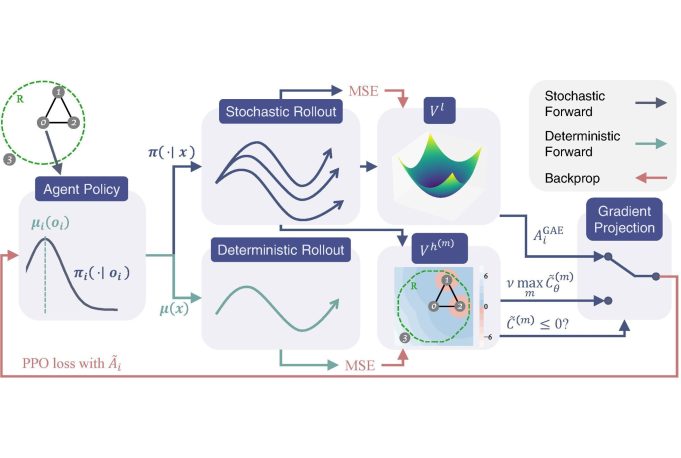
To tackle these challenges, we propose DGPPO, a new framework that simultaneously learns both a discrete graph CBF which handles neighborhood changes and input constraints, and a distributed high-performance safe policy for MAS with unknown discrete-time dynamics. We empirically validate our claims on a suite of multi-agent tasks spanning three different simulation engines. The results suggest that, compared with existing methods, our DGPPO framework obtains policies that achieve high task performance (matching baselines that ignore the safety constraints), and high safety rates (matching the most conservative baselines), with a constant set of hyperparameters across all environments.

